
The purpose of this unit is to demonstrate the importance of taking the subject variable into account in randomized block or repeated measures type designs. We have two examples of RB-3 designs. In the first example, the dependent variable is y and in the second the dependent variable is z. The means of the three groups, in each example, are exactly the same. In fact, the scores for y and z are identical, they are merely ordered differently within each group by being associated with different subjects.
use http://philender.com/courses/data/rbconex, clear
describe
Contains data from rbconex.dta
obs: 8
vars: 7 9 Nov 2000 12:53
size: 256 (98.5% of memory free)
--------------------------------------------------------------------------
1. id float %9.0g
2. y1 float %9.0g 1 y
3. z1 float %9.0g 1 z
4. y2 float %9.0g 2 y
5. z2 float %9.0g 2 z
6. y3 float %9.0g 3 y
7. z3 float %9.0g 3 z
--------------------------------------------------------------------------
correlate y1 y2 y3
(obs=8)
| y1 y2 y3
---------+---------------------------
y1 | 1.0000
y2 | 0.9997 1.0000
y3 | 0.9997 0.9998 1.0000
correlate y1 y2 y3, cov
(obs=8)
| y1 y2 y3
---------+---------------------------
y1 | 600
y2 | 593.571 587.554
y3 | 592.143 585.982 584.696
correlate z1 z2 z3
(obs=8)
| z1 z2 z3
---------+---------------------------
z1 | 1.0000
z2 | -0.5835 1.0000
z3 | -0.9997 0.5705 1.0000
correlate z1 z2 z3, cov
(obs=8)
| z1 z2 z3
---------+---------------------------
z1 | 600
z2 | -346.429 587.554
z3 | -592.143 334.411 584.696
/* reshape into long format prior to running anovas */
reshape long y z, i(id) j(group)
(note: j = 1 2 3)
Data wide -> long
--------------------------------------------------------------------
Number of obs. 8 -> 24
Number of variables 7 -> 4
j variable (3 values) -> group
xij variables:
y1 y2 y3 -> y
z1 z2 z3 -> z
---------------------------------------------------------------------
tabdisp id group, cellvar(y)
----------+-----------------
| group
id | 1 2 3
----------+-----------------
1 | 10 15 18
2 | 20 25 28
3 | 30 35 38
4 | 40 46 49
5 | 50 54 58
6 | 60 65 67
7 | 70 75 78
8 | 80 84 87
----------+-----------------
tabdisp id group, cellvar(z)
----------+-----------------
| group
id | 1 2 3
----------+-----------------
1 | 10 65 87
2 | 20 75 78
3 | 30 84 67
4 | 40 46 58
5 | 50 15 49
6 | 60 25 38
7 | 70 35 28
8 | 80 54 18
----------+-----------------
table group, contents(mean y mean z)
----------+-----------------------
group | mean(y) mean(z)
----------+-----------------------
1 | 45 45
2 | 49.875 49.875
3 | 52.875 52.875
----------+-----------------------If we run standard one-way anovas for y and z we get identical F-ratios of 0.21. This is because the standard one-way anova does not take into account the fact that the observations within each subject are not independent.
anova y group
Number of obs = 24 R-squared = 0.0200
Root MSE = 24.3053 Adj R-squared = -0.0734
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 252.75 2 126.375 0.21 0.8091
|
group | 252.75 2 126.375 0.21 0.8091
|
Residual | 12405.75 21 590.75
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565
anova z group
Number of obs = 24 R-squared = 0.0200
Root MSE = 24.3053 Adj R-squared = -0.0734
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 252.75 2 126.375 0.21 0.8091
|
group | 252.75 2 126.375 0.21 0.8091
|
Residual | 12405.75 21 590.75
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565 We can take the dependence of the observations into account by including the subjects themselves in the analysis. We do this by including the variable id in the anova command. We also include the repeated option to display the conservative p-values and the covariance matrix.
anova y group id, repeated(group)
Number of obs = 24 R-squared = 0.9998
Root MSE = .429562 Adj R-squared = 0.9997
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 12655.9167 9 1406.21296 7620.77 0.0000
|
group | 252.75 2 126.375 684.87 0.0000
id | 12403.1667 7 1771.88095 9602.45 0.0000
|
Residual | 2.58333333 14 .18452381
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565
Between-subjects error term: s
Levels: 8 (7 df)
Lowest b.s.e. variable: s
Repeated variable: group
Huynh-Feldt epsilon = 1.2972
*Huynh-Feldt epsilon reset to 1.0000
Greenhouse-Geisser epsilon = 0.9515
Box's conservative epsilon = 0.5000
------------ Prob > F ------------
Source | df F Regular H-F G-G Box
-----------+----------------------------------------------------
group | 2 684.87 0.0000 0.0000 0.0000 0.0000
Residual | 14
-----------+----------------------------------------------------
matrix list e(Srep)
symmetric e(Srep)[3,3]
c1 c2 c3
r1 600
r2 593.57143 587.55357
r3 592.14286 585.98214 584.69643
anova z group id, repeated(group)
Number of obs = 24 R-squared = 0.1239
Root MSE = 28.1449 Adj R-squared = -0.4393
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 1568.58333 9 174.287037 0.22 0.9861
|
group | 252.75 2 126.375 0.16 0.8541
id | 1315.83333 7 187.97619 0.24 0.9684
|
Residual | 11089.9167 14 792.136905
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565
Between-subjects error term: s
Levels: 8 (7 df)
Lowest b.s.e. variable: s
Repeated variable: group
Huynh-Feldt epsilon = 0.7668
Greenhouse-Geisser epsilon = 0.6679
Box's conservative epsilon = 0.5000
------------ Prob > F ------------
Source | df F Regular H-F G-G Box
-----------+----------------------------------------------------
group | 2 0.16 0.8541 0.7995 0.7688 0.7015
Residual | 14
-----------+----------------------------------------------------
matrix list e(Srep)
symmetric e(Srep)[3,3]
c1 c2 c3
r1 600
r2 -346.42857 587.55357
r3 -592.14286 334.41071 584.69643
Now the group F-ratio for y is 684.87 while the F for z is .16. Why the huge
difference? It is possible to express the degree of dependence within subjects using the intraclass correlation coefficient. The intraclass correlation measures the relative homogeneity within groups to the total variation. For the variable y the intraclass correlation is approximately .97. While for variable z the intraclass correlation is about -.32, which implies that the variability within subjects is greater than the variability between subjects.
The intraclass correlation can be obtained from a one-way anovas using subjects as the categorical independent variable. Here is the formula for the intrclass correlation,
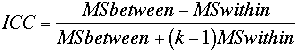
anova y id
Number of obs = 24 R-squared = 0.9798
Root MSE = 3.99479 Adj R-squared = 0.9710
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 12403.1667 7 1771.88095 111.03 0.0000
|
id | 12403.1667 7 1771.88095 111.03 0.0000
|
Residual | 255.333333 16 15.9583333
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565
display "intraclass correlation = " (1771.88-15.96)/(1771.88+2*(15.96))
intraclass correlation = .97345604
anova z id
Number of obs = 24 R-squared = 0.1039
Root MSE = 26.6255 Adj R-squared = -0.2881
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 1315.83333 7 187.97619 0.27 0.9589
|
id | 1315.83333 7 187.97619 0.27 0.9589
|
Residual | 11342.6667 16 708.916667
-----------+----------------------------------------------------
Total | 12658.50 23 550.369565
display "intraclass correlation = " (187.98-708.92)/(187.98+2*(708.92)) " truncates to " 0
intraclass correlation = -.32440747 truncates to 0
Most programs would report the intraclass correlation as zero if the computed value
is negative. In Stata, the loneway command will compute intraclass correlation.
loneway y id
One-way Analysis of Variance for y:
Number of obs = 24
R-squared = 0.9798
Source SS df MS F Prob > F
-------------------------------------------------------------------------
Between id 12403.167 7 1771.881 111.03 0.0000
Within id 255.33333 16 15.958333
-------------------------------------------------------------------------
Total 12658.5 23 550.36957
Intraclass Asy.
correlation S.E. [95% Conf. Interval]
------------------------------------------------
0.97346 0.01671 0.94071 1.00621
Estimated SD of id effect 24.19313
Estimated SD within id 3.994788
Est. reliability of a id mean 0.99099
(evaluated at n=3.00)
loneway z id
One-way Analysis of Variance for z:
Number of obs = 24
R-squared = 0.1039
Source SS df MS F Prob > F
-------------------------------------------------------------------------
Between id 1315.8333 7 187.97619 0.27 0.9589
Within id 11342.667 16 708.91667
-------------------------------------------------------------------------
Total 12658.5 23 550.36957
Intraclass Asy.
correlation S.E. [95% Conf. Interval]
------------------------------------------------
0.00000* 0.21362 0.00000 0.41869
Estimated SD of id effect .
Estimated SD within id 26.62549
Est. reliability of a id mean 0.00000*
(evaluated at n=3.00)
(*) Truncated at zero.
Linear Statistical Models Course
Phil Ender, 25apr06, 11Nov00